深度学习 Transformer 笔记
本文最后更新于:2023年11月17日 上午
Attention
概念
- 随意线索
- 有意识有目的的
- 非随意线索
- 非意识到
注意力机制
卷积、全链接、池化层斗志考虑不随意线索
注意力机制则显示地考虑随意线索
- 随意线索被称为Query
- 每个输入都是一个值(value)和不随意线索(key)的对
- 通过注意力池化层来偏向性地选择某些输入
Query (key) = values
非参注意力池化层(不要学参数)
- 给定数据 \((x_i,y_i),i=1,...n\)
- 平均池化
- 最简单
- \(f(x)=\frac{1}{n}\sum_iy_i\)
- Nadaraya-Watson核回归
- 更好的方案
- \(f(x) = \sum_{i=1}^n \frac{K(x - x_i)}{\sum_{j=1}^n K(x - x_j)} y_i,\)
- 给定一个\(x\) (query),计算最近的\(x_j\),选出\(x_j\)对应的\(y_i\)给\(f(x)\)
- 高斯核\(K(u) = \frac{1}{\sqrt{2\pi}} \exp(-\frac{u^2}{2}).\)
- \(\begin{split}\begin{aligned} f(x) &=\sum_{i=1}^n \alpha(x, x_i) y_i\\ &= \sum_{i=1}^n \frac{\exp\left(-\frac{1}{2}(x - x_i)^2\right)}{\sum_{j=1}^n \exp\left(-\frac{1}{2}(x - x_j)^2\right)} y_i \\&= \sum_{i=1}^n \mathrm{softmax}\left(-\frac{1}{2}(x - x_i)^2\right) y_i. \end{aligned}\end{split}\)
参数化的注意力机制
- 在之前的基础上,引入可以学习的\(w\)
- \(\begin{split}\begin{aligned}f(x) &= \sum_{i=1}^n \alpha(x, x_i) y_i \\&= \sum_{i=1}^n \frac{\exp\left(-\frac{1}{2}((x - x_i)w)^2\right)}{\sum_{j=1}^n \exp\left(-\frac{1}{2}((x - x_j)w)^2\right)} y_i \\&= \sum_{i=1}^n \mathrm{softmax}\left(-\frac{1}{2}((x - x_i)w)^2\right) y_i.\end{aligned}\end{split}\)
高维度
- 假设有一个查询\(\mathbf{q} \in
\mathbb{R}^q\)和\(m\)
个“键-值”对\((\mathbf{k}_1, \mathbf{v}_1),
\ldots, (\mathbf{k}_m, \mathbf{v}_m)\) , 其中\(\mathbf{k}_i \in \mathbb{R}^k\),\(\mathbf{v}_i \in \mathbb{R}^v\)。
注意力汇聚函数就被表示成值的加权和:
\[f(\mathbf{q}, (\mathbf{k}_1, \mathbf{v}_1), \ldots, (\mathbf{k}_m, \mathbf{v}_m)) = \sum_{i=1}^m \alpha(\mathbf{q}, \mathbf{k}_i) \mathbf{v}_i \in \mathbb{R}^v\]
\[\alpha(\mathbf{q}, \mathbf{k}_i) = \mathrm{softmax}(a(\mathbf{q}, \mathbf{k}_i)) = \frac{\exp(a(\mathbf{q}, \mathbf{k}_i))}{\sum_{j=1}^m \exp(a(\mathbf{q}, \mathbf{k}_j))} \in \mathbb{R}.\]
- \(\alpha\):计算权重的函数
- \(a\):计算\(q,k_j\)相关度的函数(可以是距离)
注意力函数设计
Additive Attention
- 加性注意力
\[a(\mathbf q, \mathbf k) = \mathbf w_v^\top \text{tanh}(\mathbf W_q\mathbf q + \mathbf W_k \mathbf k) \in \mathbb{R},\]
其中可学习的参数是\(\mathbf W_q\in\mathbb R^{h\times q}\)、\(\mathbf W_k\in\mathbb R^{h\times k}\) 和 \(\mathbf w_v\in\mathbb R^{h}\)。将查询和键连结起来后输入到一个多层感知机(MLP)中, 感知机包含一个隐藏层,其隐藏单元数是一个超参数。 通过使用作为激活函数,并且禁用偏置项。
key和query拼起来,放到一个隐藏层中去计算好处:
key和value可以是任意长度
Scale Dot-Product Attention
如果
query和key都是同样的长度\(d\),\(\mathbf Q\in\mathbb R^{n\times d}\),\(\mathbf K\in\mathbb R^{m\times d}\)
\(a(\mathbf q, \mathbf k) = \mathbf{q}^\top \mathbf{k} /\sqrt{d}.\)
向量化版本
n个Query,m个key和value- \(Q\in\mathbb R^{n\times d},K\in\mathbb R^{m\times d},V\in\mathbb R^{m\times v}\)
- 注意力分数:\(a(Q,K)=QK^T/\sqrt{d}\in
\mathbb R^{n\times
m}\),第
i行表示第i个Query的权重 - 注意力池化:\(f=softmax(a(Q,K))V\in\mathbb R^{n\times v}\)
代码
注意力机制
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
注意力函数
加性注意力
1 | |
缩放点乘积注意力
1 | |
总结
几个概念
- Query、Key、Value
- \(Attention(Query,Source) =
\sum_{i=1}^{L_x}Similarity(Query,Key_i)*Value_i\)
- 简单地说就是计算
Query和Key的相似程度作为对应Value的权重进行加权
- 简单地说就是计算
计算阶段
根据
Query和Key计算权重系数- 根据
Query和Key计算两者的相似性或相关性 - 对第一阶段的原始分值进行归一化处理
- 根据
根据权重系数对
value进行加权求和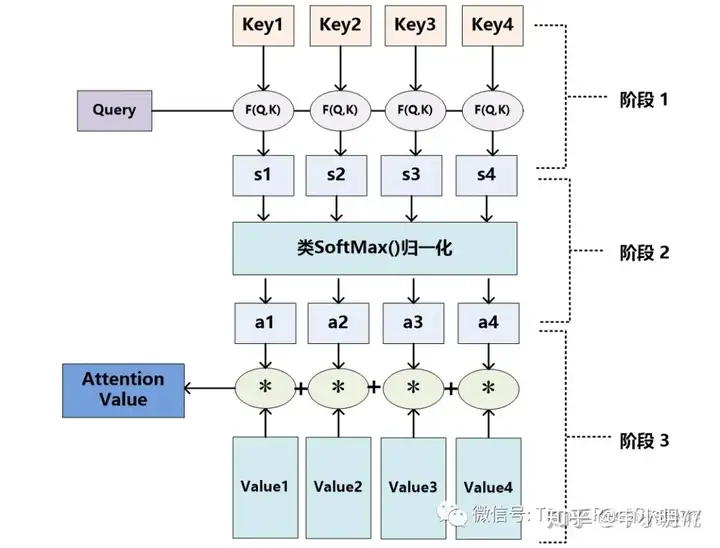
注意力分数是
query和key的相似度,注意力全中是分数softmax的结果两种常见的注意力分数计算方式
- 将
query和key合并起来进入一个单输出单隐藏层的MLP - 直接将
query和key做内积
- 将
加入Attention的Seq2Seq
核心
- 传统的Seq2Seq
- 用上一层的Hidden状态预测下一个
- Attention的Seq2Seq
- encoder层建立了输入和输出对应隐状态的Key和Value Pair
- decoder层用上一时刻的输出作为Query去拿这次输出应该对应的隐状态
- Key和Value是对RNN编码器的每一个词的输出
- Query是解码器对上一个词的预测输出

总结
- Seq2Seq通过隐状态在编码器和解码器中传递信息
- 注意力机制可以根据解码器RNN的输入来匹配到合适的编码器RNN的输出来更有效的传递信息
代码
1 | |
1 | |