本文最后更新于:2023年7月23日 晚上
注:
Pytorch 的RNN 不带输出层 需要自己定义和计算输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def rnn (inputs, state, params ):for X in inputs:return torch.cat(outputs, dim=0 ), (H,)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class RNNModel (nn.Module):"""循环神经网络模型""" def __init__ (self, rnn_layer, vocab_size, **kwargs ):super (RNNModel, self).__init__(**kwargs)if not self.rnn.bidirectional:1 else :2 2 , self.vocab_size)def forward (self, inputs, state ):1 , Y.shape[-1 ])))return output, statedef begin_state (self, device, batch_size=1 ):if not isinstance (self.rnn, nn.LSTM):return torch.zeros((self.num_directions * self.rnn.num_layers,else :return (torch.zeros((
门控循环单元
概念
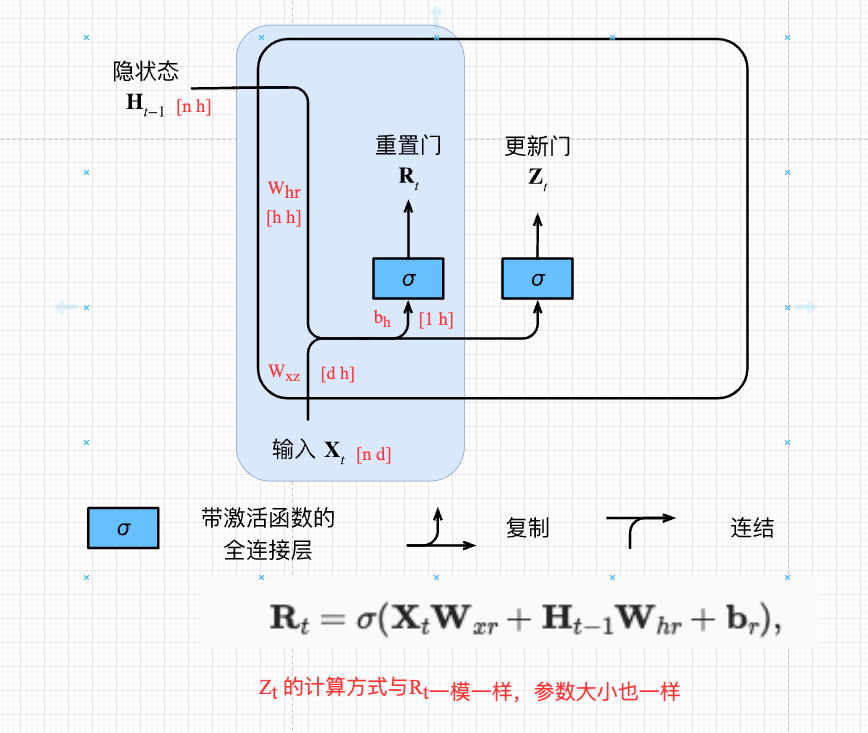
GRU (Gated)
特点
不是每一个观察值都同等重要
想只记住相关的观察需要:
能关注到机制(更新门) Update Gate
能遗忘的机制(重置门)Reset Gate
gru-1
核心
门
\[\begin{split}\begin{aligned}
\mathbf{R}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xr} + \mathbf{H}_{t-1}
\mathbf{W}_{hr} +
\mathbf{b}_r)\end{aligned}\end{split}\]
[n d] [d h] + [n h] [ h h] + [1 h]
n :batch_size ;
d :input_dimension ;
h :hidden_size
最终目的都是计算\(H_t\) 、\(Y\)
更新门
\[\begin{split}\begin{aligned}
\mathbf{R}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xr} + \mathbf{H}_{t-1}
\mathbf{W}_{hr} + \mathbf{b}_r)\end{aligned}\end{split}\]
重置门
\[\begin{split}\begin{aligned}
\mathbf{Z}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xz} + \mathbf{H}_{t-1}
\mathbf{W}_{hz} + \mathbf{b}_z),
\end{aligned}\end{split}\]
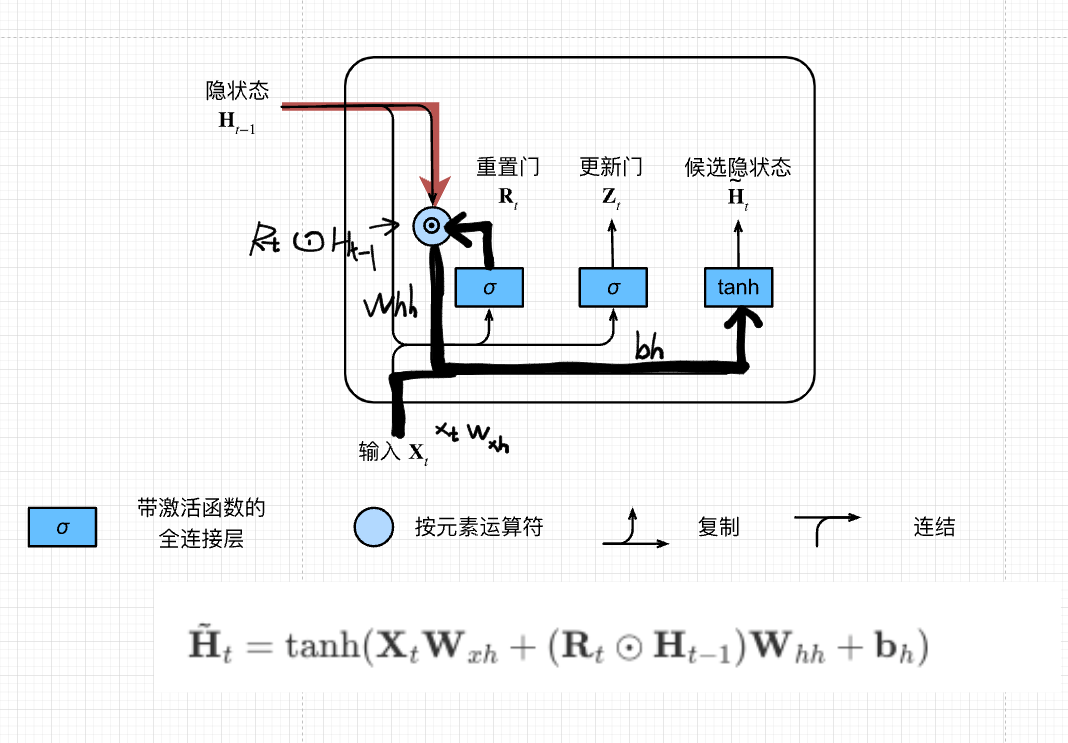
候选隐状态
用来生成真正的隐状态
\(R_t\) 用来表示对\(H_{t-1}\) (上一步的隐状态)信息的保留量,更新新的隐藏状态的时候要用到多少过去的信息\(\odot\) 对应位置的元素相乘
\[\tilde{\mathbf{H}}_t =
\tanh(\mathbf{X}_t \mathbf{W}_{xh} + \left(\mathbf{R}_t \odot
\mathbf{H}_{t-1}\right) \mathbf{W}_{hh} + \mathbf{b}_h)\]
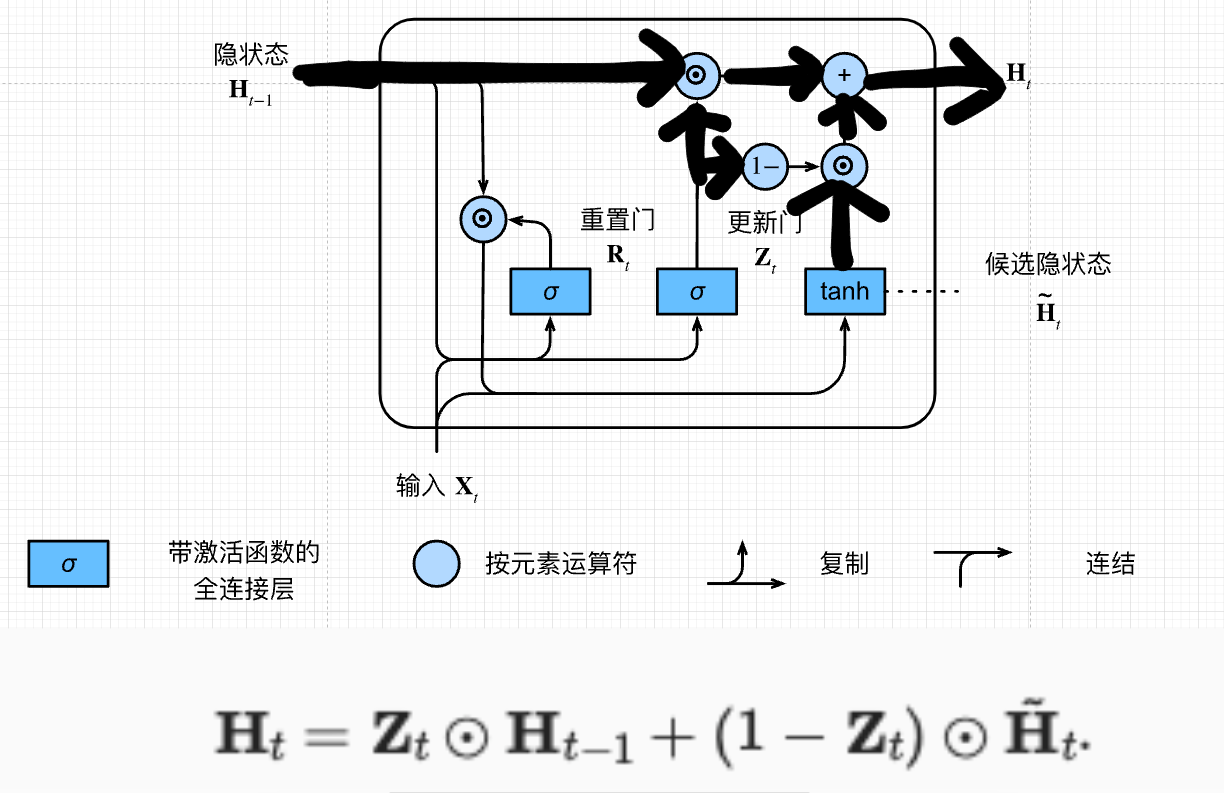
最终隐状态
\[\mathbf{H}_t = \mathbf{Z}_t \odot
\mathbf{H}_{t-1} + (1 - \mathbf{Z}_t) \odot
\tilde{\mathbf{H}}_t.\]
\(Z_t\) 点乘上一次的隐状态 + \(1-Z_t\) 点乘候选隐状态\(Z_t=0\) 相当于RNN算真正的隐藏层状态的时候要用多少新的候选隐藏状态的信息
重置门与更新门
候选隐状态
更新门与候选隐状态更新ht
重置门,是不是过去的信息都不要,有助于捕获序列中的短期依赖关系
更新门,要不要根据当前的\(x_t\) 去更新\(H\) 有助于补货序列中的长期依赖关系
代码
手动实现
1 2 3 4 5 6 import torchfrom torch import nnfrom d2l import torch as d2l32 , 35
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def get_params (vocab_size, num_hiddens, device ):def normal (shape ):return torch.randn(size=shape, device=device)*0.01 def three ():return (normal((num_inputs, num_hiddens)),for param in params:True )return params
1 2 def init_gru_state (batch_size, num_hiddens, device ):return (torch.zeros((batch_size, num_hiddens), device=device), )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def gru (inputs, state, params ):for X in inputs:1 - Z) * H_tildareturn torch.cat(outputs, dim=0 ), (H,)
1 2 3 4 5 vocab_size, num_hiddens, device = len (vocab), 256 , d2l.try_gpu()500 , 1 len (vocab), num_hiddens, device, get_params,
简洁实现
1 2 3 4 5 6 7 num_inputs = vocab_sizelen (vocab))
LSTM
概念
长短期记忆网络
核心
忘记门:将值朝0减少
输入门:决定是不是忽略掉输入数据
输出门:决定是不是使用隐状态
lstm-0
lstm-3
\[\begin{split}\begin{aligned}
\mathbf{I}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xi} +
\mathbf{H}_{t-1} \mathbf{W}_{hi} + \mathbf{b}_i),\\
\mathbf{F}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xf} +
\mathbf{H}_{t-1} \mathbf{W}_{hf} + \mathbf{b}_f),\\
\mathbf{O}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xo} +
\mathbf{H}_{t-1} \mathbf{W}_{ho} + \mathbf{b}_o),
\end{aligned}\end{split}\]
\[\tilde{\mathbf{C}}_t =
\text{tanh}(\mathbf{X}_t \mathbf{W}_{xc} + \mathbf{H}_{t-1}
\mathbf{W}_{hc} + \mathbf{b}_c),\]
[n d] [d h] + [n h] [ h h] + [1 h]
n :batch_size ;
d :input_dimension ;
h :hidden_size
\[\mathbf{C}_t = \mathbf{F}_t \odot
\mathbf{C}_{t-1} + \mathbf{I}_t \odot \tilde{\mathbf{C}}_t.\]
\[\mathbf{H}_t = \mathbf{O}_t \odot
\tanh(\mathbf{C}_t).\]
代码
手动实现
1 2 3 4 5 6 import torchfrom torch import nnfrom d2l import torch as d2l32 , 35
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def get_lstm_params (vocab_size, num_hiddens, device ):def normal (shape ):return torch.randn(size=shape, device=device)*0.01 def three ():return (normal((num_inputs, num_hiddens)),for param in params:True )return params
1 2 3 def init_lstm_state (batch_size, num_hiddens, device ):return (torch.zeros((batch_size, num_hiddens), device=device),
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def lstm (inputs, state, params ):for X in inputs:return torch.cat(outputs, dim=0 ), (H, C)
1 2 3 4 5 vocab_size, num_hiddens, device = len (vocab), 256 , d2l.try_gpu()500 , 1 len (vocab), num_hiddens, device, get_lstm_params,
简洁实现
1 2 3 4 5 6 num_inputs = vocab_sizelen (vocab))
深度循环神经网络
概念
用多个隐藏层来获取非线形性
一般神经网络不能够做的很宽 ,因为会overfitting
多个隐藏层变深,每一层做一点点非线性,很多层叠加起来、
输入->隐藏层->隐藏层->隐藏层...->隐藏层 ->输出
第\(l\) 层隐状态计算公式
\({H}_t^{(l)} = \phi_l({H}_t^{(l-1)}
{W}_{xh}^{(l)} + {H}_{t-1}^{(l)} {W}_{hh}^{(l)} +
b_h^{(l)}),\) \(H_t^1=f_1(H_{t-1}^1,X_t)\) \(H_t^j=f_j(H_{t-1}^j,H_t^{j-1})\) \(O_t=g(H_t^L)\)
代码
1 2 3 4 5 6 import torchfrom torch import nnfrom d2l import torch as d2l32 , 35
1 2 3 4 5 6 7 vocab_size, num_hiddens, num_layers = len (vocab), 256 , 2 len (vocab))
1 2 num_epochs, lr = 500 , 2 1.0 , num_epochs, device)
双向循环神经网络
概念
后面的信息同样重要
用后面的隐状态更新前面的隐状态
核心
前向隐状态
\(\begin{split}\begin{aligned}
\overrightarrow{\mathbf{H}}_t &= \phi(\mathbf{X}_t
\mathbf{W}_{xh}^{(f)} + \overrightarrow{\mathbf{H}}_{t-1}
\mathbf{W}_{hh}^{(f)} + \mathbf{b}_h^{(f)})
\end{aligned}\end{split}\)
后向隐状态
\(\begin{split}\begin{aligned}
\overleftarrow{\mathbf{H}}_t &= \phi(\mathbf{X}_t
\mathbf{W}_{xh}^{(b)} + \overleftarrow{\mathbf{H}}_{t+1}
\mathbf{W}_{hh}^{(b)} + \mathbf{b}_h^{(b)})
\end{aligned}\end{split}\)
隐状态Concat
\(H_t=[\overrightarrow{\mathbf{H}}_t,\overleftarrow{\mathbf{H}}_t]\)
计算输出
总结
双向循环神经网络通过反向更新的隐藏层来利用反向时间信息
通常用来对序列抽取特征、填空,而不是预测未来(不适合做推理)
代码
直接调用框架
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import torchfrom torch import nnfrom d2l import torch as d2l32 , 35 , d2l.try_gpu()len (vocab), 256 , 2 True )len (vocab))500 , 1
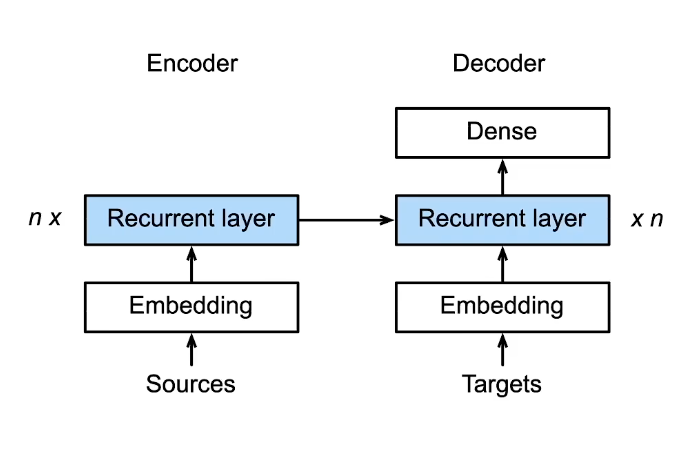
编码器与解码器
概念
编码器
解码器
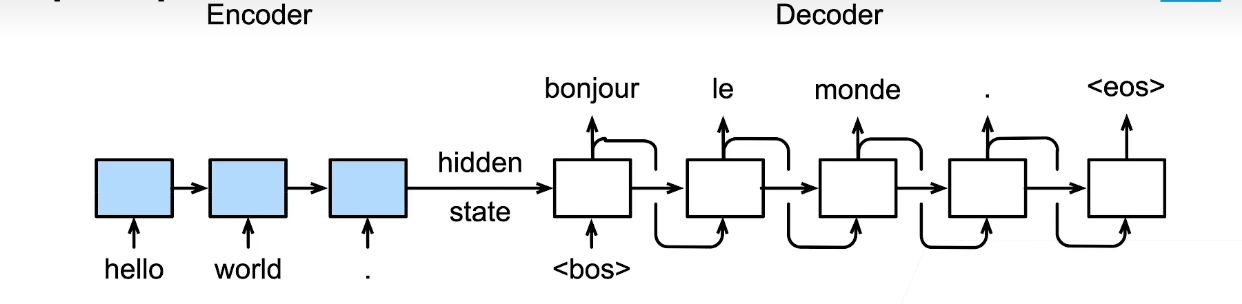
架构
encoder-decoder
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from troch import nnclass Encoder (nn.Module):def __init__ (self,**kwargs ):super (Encoder,self).__init__(**kwargs)def forward (self, X, *args )raise NotImplementedErrorclass Decoder (nn.module):def __init__ (self, **kwargs ):super (Decoder, self).__init__(**kwargs)def init_state (self, enc_outputs, *args ):raise NotImplementedErrordef forward (self, X, state ):raise NotImplementedErrorclass EncoderDecoder (nn.Module):def __init__ (self, encoder, decoder, **kwargs ):super (EncoderDecoder, self).__init__(**kwargs)def forwarf (self, enc_X, dec_X, *args ):return self.decoder(dev_X, dec_state)
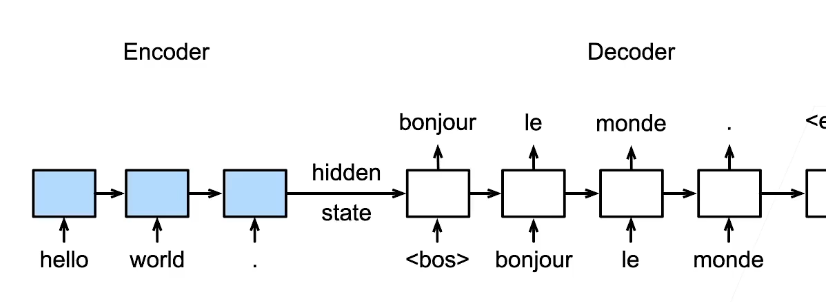
Seq2Seq
概念
核心
编码器是RNN,读取输入句子
可以是双向(一个句子正向看一下,反向看一下都可以)
解码器使用另外一个RNN来输出
Seq2Seq
横向:hidden state 传播
纵向:上一个词作为输入预测下一个词
细节
编码器是没有输出的RNN
编码器最后时间步的隐状态用作解码器的最初的隐状态
最后一层的RNN在最后时刻的隐状态和句子的Embedding的输入结合起来作为Decoder的输入
解码器def forward(self,X,state)
编码器不需要输出,最后时刻(一层)的隐状态就是它的输出
Encoder_Decoder
训练
训练时解码器使用目标句子作为输入,给的都是正确的单词
就算Decoder部分,第一次<bos> ->
bonjour不对的话,第二次还是会给bonjour(正确的单词)去训练
Seq2Seq_train
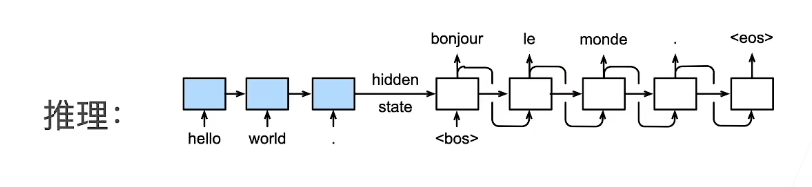
推理/预测
Seq2Seq_Pred
评价生成序列的好坏BLEU
\(p_n\) 是预测中所有n-gram的精度
标签序列 A B C D E F,预测序列 A B B C D
\(p_1 = \frac{4}{5}\) ,\(p_2=\frac{3}{4}\) ,\(p_3=\frac{1}{3}\) ,\(p_4=0\) \(p_1\)
uni-gram,A出现,B出现,第二个B没出现,C出现,D出现,
4/5\(p_2\) bil-gram,A
B出现,B B没出现,B C没现,C D出现, 3/4\(p_3\) tri-gram,A B
B 没出现,B B C 没出现,B C D出现, 1/3\(p_4\) 4-gram,A B B C
没出现,B B C D没出现 ,0 BLEU定义
前半部分,惩罚过短的预测
后半部分,长匹配拥有高权重
\[\begin{align}\exp\left(\min\left(0, 1 -
\frac{\mathrm{len}_{\text{label}}}{\mathrm{len}_{\text{pred}}}\right)\right)
\prod_{n=1}^k p_n^{1/2^n}\end{align}\]
总结
Seq2Seq 冲一个句子生成另一个句子编码器和解码器都是RNN
将编码器最后时间隐状态来初始化解码器的隐状态来完成信息传递
常用BLEU 来衡量生成序列的好坏
代码
1 2 3 4 5 import collectionsimport mathimport torchfrom torch import nnfrom d2l import torch as d2l
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Seq2SeqEncoder (d2l.Encoder):def __init__ (self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0 , **kwargs )super (Seq2SeqEncoder,self).__init__(**kwargs)def forward (self, X, *args ):1 ,0 ,2 )return output, state10 , embed_size=8 , num_hidden=16 , num_layers=2 )eval () 4 ,7 ),dtype=torch.long)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Seq2SeqDecoder (d2l.Decoder):def __init__ (self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0 , **kwargs ):super (Seq2SeqDecoder, self).__init__(**kwargs)def init_state (self, enc_outputs, *args ):return enc_outputs[1 ]def forward (self, X, state ):1 , 0 , 2 )1 ].repeat(X.shape[0 ], 1 , 1 )2 )1 , 0 , 2 )return output, state
1 2 3 4 5 6 7 8 9 10 11 12 13 def sequence_mask (X, valid_len, value=0 ):"""在序列中屏蔽不相关的项""" 1 )None , :] < valid_len[:, None ]return X1 , 2 , 3 ], [4 , 5 , 6 ]])1 , 2 ]))
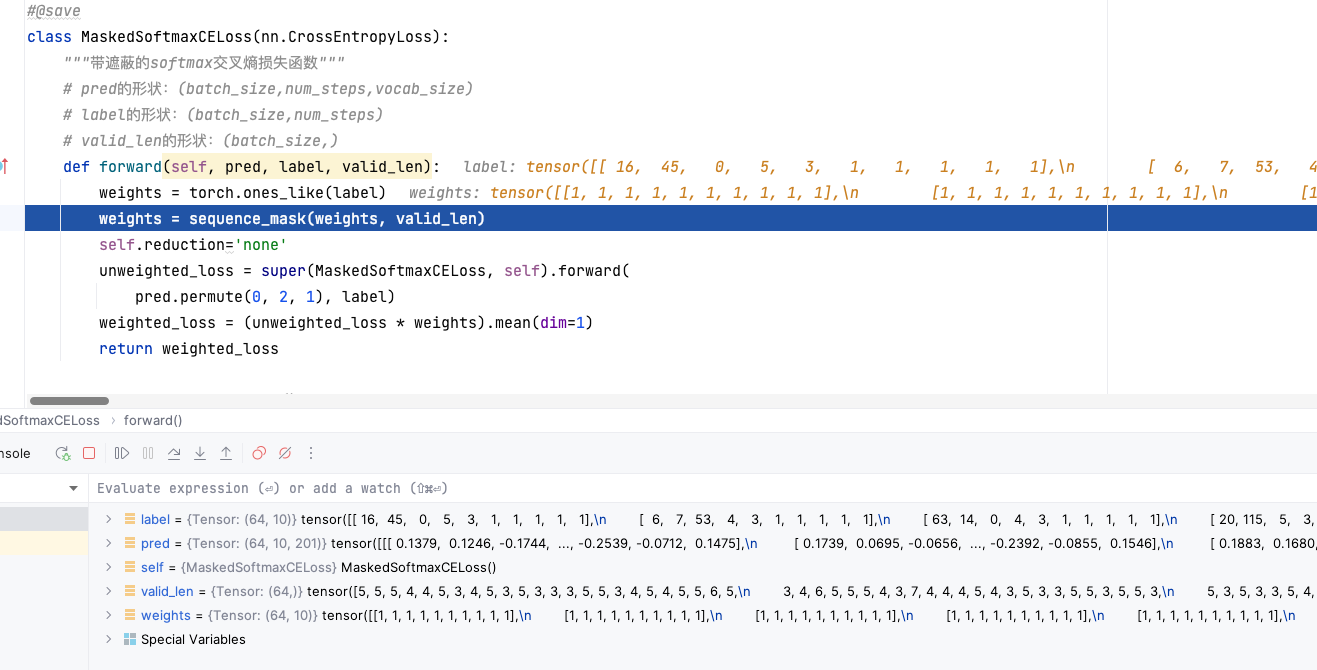
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class MaskedSoftmaxCELoss (nn.CrossEntropyLoss):"""带遮蔽的softmax交叉熵损失函数""" def forward (self, pred, label, valid_len ):'none' super (MaskedSoftmaxCELoss, self).forward(0 , 2 , 1 ), label)1 )return weighted_loss
MaskCrossEntropy_debug
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 def train_seq2seq (net, data_iter, lr, num_epochs, tgt_vocab, device ):"""训练序列到序列模型""" def xavier_init_weights (m ):if type (m) == nn.Linear:if type (m) == nn.GRU:for param in m._flat_weights_names:if "weight" in param:'epoch' , ylabel='loss' ,10 , num_epochs])for epoch in range (num_epochs):2 ) for batch in data_iter:for x in batch]'<bos>' ]] * Y.shape[0 ],1 , 1 )1 ]], 1 ) sum ().backward() 1 )sum ()with torch.no_grad():sum (), num_tokens)if (epoch + 1 ) % 10 == 0 :1 , (metric[0 ] / metric[1 ],))print (f'loss {metric[0 ] / metric[1 ]:.3 f} , {metric[1 ] / timer.stop():.1 f} ' f'tokens/sec on {str (device)} ' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 embed_size, num_hiddens, num_layers, dropout = 32 , 32 , 2 , 0.1 64 , 10 0.005 , 300 , d2l.try_gpu()len (src_vocab), embed_size, num_hiddens, num_layers,len (tgt_vocab), embed_size, num_hiddens, num_layers,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 def predict_seq2seq (net, src_sentence, src_vocab, tgt_vocab, num_steps, device, save_attention_weights=False ):"""序列到序列模型的预测""" eval ()' ' )] + ['<eos>' ]]len (src_tokens)], device=device)'<pad>' ])0 )'<bos>' ]], dtype=torch.long, device=device), dim=0 )for _ in range (num_steps):2 )0 ).type (torch.int32).item()if save_attention_weights:if pred == tgt_vocab['<eos>' ]:break return ' ' .join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def bleu (pred_seq, label_seq, k ): """计算BLEU""" ' ' ), label_seq.split(' ' )len (pred_tokens), len (label_tokens)min (0 , 1 - len_label / len_pred))for n in range (1 , k + 1 ):0 , collections.defaultdict(int )for i in range (len_label - n + 1 ):' ' .join(label_tokens[i: i + n])] += 1 for i in range (len_pred - n + 1 ):if label_subs[' ' .join(pred_tokens[i: i + n])] > 0 :1 ' ' .join(pred_tokens[i: i + n])] -= 1 pow (num_matches / (len_pred - n + 1 ), math.pow (0.5 , n))return score
1 2 3 4 5 6 7 'go .' , "i lost ." , 'he\'s calm .' , 'i\'m home .' ]'va !' , 'j\'ai perdu .' , 'il est calme .' , 'je suis chez moi .' ]for eng, fra in zip (engs, fras):print (f'{eng} => {translation} , bleu {bleu(translation, fra, k=2 ):.3 f} ' )
束搜索(Beam Search)
背景
在Seq2Seq 中,使用 贪心算法来预测输出序列
将当前时刻预测概率最大的词输出
效率高,可能不是最优
问题:当前步选择的词从整个句子来看不一定是优的
穷举法: 词典大小\(n\) ,序列长度\(T\) ,计算\(n^T\) 次,不可行。
贪心算法: A 0.5 -> B 0.4, A,B -> C 0.4,
A,B,C ->. <eos> 0.6
0.5 * 0.5 * 0.4 * 0.6 = 0.048
其他可能: A 0.5 -> B 0.3, A,B -> C 0.6,
A,B,C ->. <eos> 0.6
0.5 * 0.3 * 0.6 * 0.6 = 0.054
../_images/s2s-prob1.svg
../_images/s2s-prob2.svg
概念
保存最好的\(k\) 个候选
在每个时刻, 对每一个候选新加一项(\(n\) 种可能),在\(kn\) 个选项中选出最好的\(k\) 个
../_images/beam-search.svg
基本流程:
\(k=2\) ,句子开始num_step1:
num_step2:
选完后在对\(A\) 、\(C\) 计算全部(\(n=5\) )种可能,共\(k\cdot n\) ,10种
在10个选项中选出最好的2个
组成\(A,B\) 、\(C,E\)
num_step3:
选完后在对\(A,B\) 、\(C,E\) 计算全部(\(n=5\) )种可能,共\(k\cdot n\) ,10种
在10个选项中选出最好的2个
组成\(A,B,D\) 、\(C,E,D\)
复杂度
时间复杂度 \(O(k\cdot n \cdot T)\)
\(k=5\) , \(n=1000\) , \(T=10\) ,复杂度:\(5 \times 10^5\)
每个候选的最终分数
\(\frac{1}{L^\alpha} \log P(y_1, \ldots,
y_{L}\mid \mathbf{c}) = \frac{1}{L^\alpha} \sum_{t'=1}^L \log
P(y_{t'} \mid y_1, \ldots, y_{t'-1}, \mathbf{c}),\) 通常\(\alpha=0.75\)
其中是最终候选序列的长度, 通常设置为。 因为一个较长的序列在
的求和中会有更多的对数项, 因此分母中的用于惩罚长序列。
一些问题
因为每个词概率不可能都等于
1,所以分数肯定越乘越小,导致模型容易去选择短的句子
所以会有
\(\log P(y_1, \ldots, y_{L}\mid
\mathbf{c})\) 值为负数\(L\) :句子长度\(\alpha\) :通常0.75句子长度越长,\(\frac{1}{L^{\alpha}}\) 越小,\(\frac{1}{L^{\alpha}}\log P(y_1, \ldots, y_{L}\mid
\mathbf{c})\) 越大
用于惩罚长句子
总结
束搜索在每次搜索时候保存\(k\) 个最好的候选
\(k=1\) 贪心搜索语音识别的时候为了实时性,\(k\) 会取小一点