本文最后更新于:2023年7月23日 晚上
序列模型
数据
现实世界中很多数据是有时序结构的
音乐、语言、文本,很多数据都是连续的
统计工具
模型
模型2
序列模型
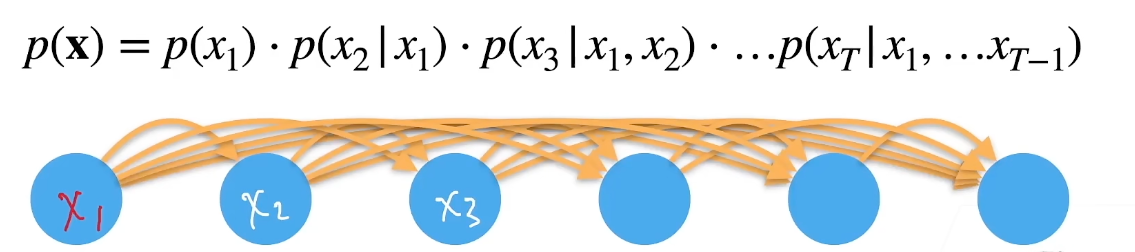
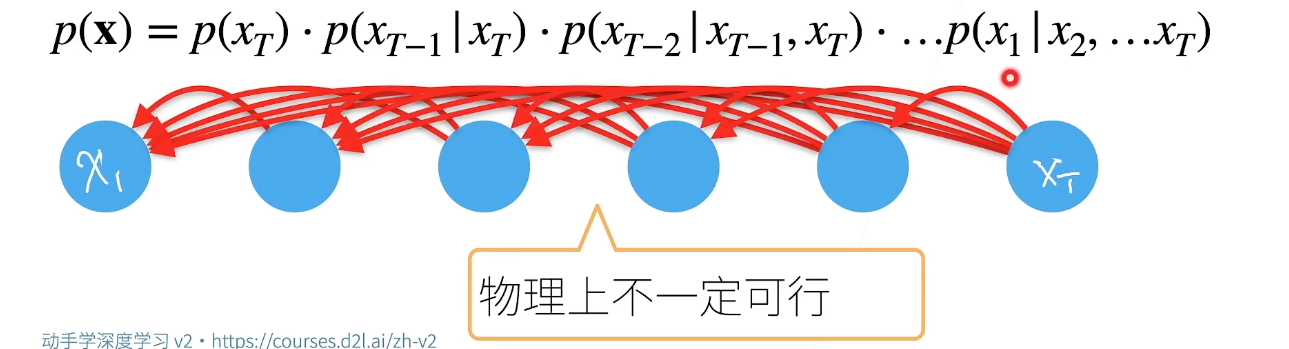
对条件概率建模,自回归模型
给一定数据,预测另外一组数据时用前面给的数据
核心:计算\(P\) 、\(f(x_1,...x_{t-1})\)
自回归模型
马尔科夫假设
\[p(x_t|x_1,...x_{t-1})=p(x_t|x_{t-\tau},...x_{t-1})=p(x_t|f(x_{t-\tau},...x_{t-1}))\]
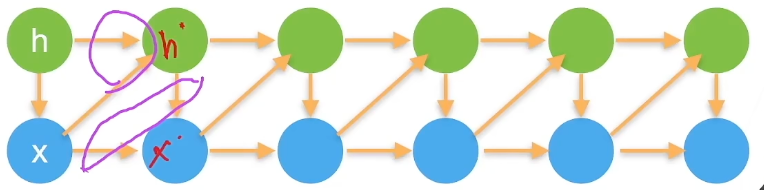
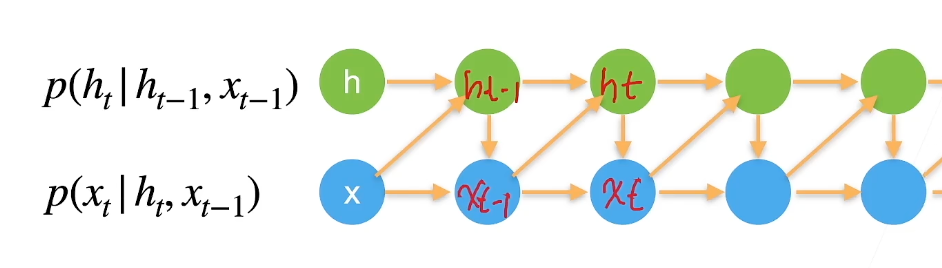
潜变量模型
引入潜变量\(h_t\) 来表示过去信息\(h_t=f(x_1,...x_{t-1})\)
\(x_t = p(x_t|h_t)\) 新的\(h'\) 和前面的\(h\) 和\(x\) 相关(模型1)
给定前面的\(x\) 和新的\(h'\) 计算新的\(x'\) (模型2)
潜变量自回归模型
潜变量自回归模型
总结
时序模型中,当前数据只跟前面观察到的数据相关
自回归模型使用自身过去数据来预测未来
马尔可夫模型假设当前只跟最近少数数据相关,从而简化模型
潜变量模型使用潜变量来概括历史信息
代码
1 2 3 4 5 6 7 8 9 %matplotlib inlineimport torchfrom torch import nnfrom d2l import torch as d2l1000 1 , T + 1 , dtype=torch.float32)0.01 * time) + torch.normal(0 , 0.2 , (T,))'time' , 'x' , xlim=[1 , 1000 ], figsize=(6 , 3 ))
1 2 3 4 5 6 7 8 9 10 11 tau = 4 for i in range (tau):1 , 1 ))16 , 600 True )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def init_weights (m ):if type (m) == nn.Linear:def get_net ():4 , 10 ),10 , 1 ))return net'none' )
1 2 3 4 5 6 7 8 9 10 11 12 13 def train (net, train_iter, loss, epochs, lr ):for epoch in range (epochs):for X, y in train_iter:sum ().backward()print (f'epoch {epoch + 1 } , ' f'loss: {d2l.evaluate_loss(net, train_iter, loss):f} ' )5 , 0.01 )
1 2 3 4 5 onestep_preds = net(features)'time' ,'x' , legend=['data' , '1-step preds' ], xlim=[1 , 1000 ],6 , 3 ))
1 2 3 4 5 6 7 8 9 10 11 multistep_preds = torch.zeros(T)for i in range (n_train + tau, T):1 , -1 )))'time' ,'x' , legend=['data' , '1-step preds' , 'multistep preds' ],1 , 1000 ], figsize=(6 , 3 ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 max_steps = 64 1 , tau + max_steps))for i in range (tau):1 ]for i in range (tau, tau + max_steps):1 )1 , 4 , 16 , 64 )1 : T - max_steps + i] for i in steps],1 ].detach().numpy() for i in steps], 'time' , 'x' ,f'{i} -step preds' for i in steps], xlim=[5 , 1000 ],6 , 3 ))
文本预处理
代码
1 2 3 import collectionsimport refrom d2l import torch as d2l
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 'time_machine' ] = (d2l.DATA_URL + 'timemachine.txt' ,'090b5e7e70c295757f55df93cb0a180b9691891a' )def read_time_machine (): """将时间机器数据集加载到文本行的列表中""" with open (d2l.download('time_machine' ), 'r' ) as f:return [re.sub('[^A-Za-z]+' , ' ' , line).strip().lower() for line in lines]print (f'# 文本总行数: {len (lines)} ' )print (lines[0 ])print (lines[10 ])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def tokenize (lines, token='word' ): """将文本行拆分为单词或字符词元""" if token == 'word' :return [line.split() for line in lines]elif token == 'char' :return [list (line) for line in lines]else :print ('错误:未知词元类型:' + token)for i in range (11 ):print (tokens[i])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 class Vocab : """文本词表""" def __init__ (self, tokens=None , min_freq=0 , reserved_tokens=None ):if tokens is None :if reserved_tokens is None :sorted (counter.items(), key=lambda x: x[1 ],True )'<unk>' ] + reserved_tokensfor idx, token in enumerate (self.idx_to_token)}for token, freq in self._token_freqs:if freq < min_freq:break if token not in self.token_to_idx:len (self.idx_to_token) - 1 def __len__ (self ):return len (self.idx_to_token)def __getitem__ (self, tokens ):if not isinstance (tokens, (list , tuple )):return self.token_to_idx.get(tokens, self.unk)return [self.__getitem__(token) for token in tokens]def to_tokens (self, indices ):if not isinstance (indices, (list , tuple )):return self.idx_to_token[indices]return [self.idx_to_token[index] for index in indices] @property def unk (self ): return 0 @property def token_freqs (self ):return self._token_freqsdef count_corpus (tokens ): """统计词元的频率""" if len (tokens) == 0 or isinstance (tokens[0 ], list ):for line in tokens for token in line]return collections.Counter(tokens)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def load_corpus_time_machine (max_tokens=-1 ): """返回时光机器数据集的词元索引列表和词表""" 'char' )for line in tokens for token in line]if max_tokens > 0 :return corpus, vocablen (corpus), len (vocab)
语言模型数据集
目的
对一个文档,甚至是一个词元序列进行建模。
\[P(x_1, x_2, \ldots, x_T) = \prod_{t=1}^T
P(x_t \mid x_1, \ldots, x_{t-1}).\]
\[P(\text{deep}, \text{learning},
\text{is}, \text{fun}) = P(\text{deep})
P(\text{learning} \mid \text{deep}) P(\text{is} \mid \text{deep},
\text{learning}) P(\text{fun} \mid \text{deep}, \text{learning},
\text{is}).\]
马尔可夫模型
涉及一个、两个和三个变量的概率公式分别被称为
一元语法 (unigram)、二元语法 (bigram)和三元语法 (trigram)模型。
\[\begin{split}\begin{aligned}P(x_1, x_2,
x_3, x_4) &= P(x_1) P(x_2) P(x_3) P(x_4),\\
P(x_1, x_2, x_3, x_4) &= P(x_1) P(x_2 \mid x_1) P(x_3 \mid x_2)
P(x_4 \mid x_3),\\
P(x_1, x_2, x_3, x_4) &= P(x_1) P(x_2 \mid x_1) P(x_3 \mid x_1,
x_2) P(x_4 \mid x_2, x_3).
\end{aligned}\end{split}\]
读取长时间序列数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def seq_data_iter_random (corpus, batch_size, num_steps ): """使用随机抽样生成一个小批量子序列""" 0 , num_steps - 1 ):]len (corpus) - 1 ) // num_stepslist (range (0 , num_subseqs * num_steps, num_steps))def data (pos ):return corpus[pos: pos + num_steps]for i in range (0 , batch_size * num_batches, batch_size):for j in initial_indices_per_batch]1 ) for j in initial_indices_per_batch]yield torch.tensor(X), torch.tensor(Y)range (0 ,35 ),bathch_size=2 ,num_steps=5 )
没有random.shuffle
1 2 3 4 5 6 7 8 9 10 11 12 13 def seq_data_iter_sequential (corpus, batch_size, num_steps ): """使用顺序分区生成一个小批量子序列""" 0 , num_steps)len (corpus) - offset - 1 ) // batch_size) * batch_size1 : offset + 1 + num_tokens])1 ), Ys.reshape(batch_size, -1 )1 ] // num_stepsfor i in range (0 , num_steps * num_batches, num_steps):yield X, Y
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class SeqDataLoader : """加载序列数据的迭代器""" def __init__ (self, batch_size, num_steps, use_random_iter, max_tokens ):if use_random_iter:else :def __iter__ (self ):return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)def load_data_time_machine (batch_size, num_steps, use_random_iter=False , max_tokens=10000 ):"""返回时光机器数据集的迭代器和词表""" return data_iter, data_iter.vocab
循环神经网络
独热编码
概念
方法
注意
1 2 3 4 5 6 7 8 10 ).reshape((2 , 5 ))28 ).shape
梯度裁剪
原因
对于长度为的序列,我们在迭代中计算这个时间步上的梯度,
将会在反向传播过程中产生长度为的矩阵乘法链。 当\(\mathcal{O}(T)\)
概念
如果梯度长度超过\(\theta\) ,那么拖影回长度$ $
\[\mathbf{g} \leftarrow \min\left(1,
\frac{\theta}{\|\mathbf{g}\|}\right) \mathbf{g}.\]
困惑度
概念
下一个词元的实际选择数的调和平均数
用于衡量语言模型的质量
我们在引入softmax回归 ( 3.4.7节 )时定义了熵、惊异和交叉熵。
如果想要压缩文本,我们可以根据当前词元集预测的下一个词元。
一个更好的语言模型应该能让我们更准确地预测下一个词元。
因此,它应该允许我们在压缩序列时花费更少的比特。
所以我们可以通过一个序列中所有的个词元的交叉熵损失的平均值来衡量:
\[\frac{1}{n} \sum_{t=1}^n -\log P(x_t
\mid x_{t-1}, \ldots, x_1),\]
其中由语言模型给出, 是在时间步从该序列中观察到的实际词元。
这使得不同长度的文档的性能具有了可比性。
由于历史原因,自然语言处理的科学家更喜欢使用一个叫做困惑度 (perplexity)的量。
简而言之,它是 交叉熵损失的平均值的指数:
\[\exp\left(-\frac{1}{n} \sum_{t=1}^n
\log P(x_t \mid x_{t-1}, \ldots, x_1)\right).\]
预测情况
在最好的情况下,模型总是完美地估计标签词元的概率为1。
在这种情况下,模型的困惑度为1。
在最坏的情况下,模型总是预测标签词元的概率为0。
在这种情况下,困惑度是正无穷大。
在基线上,该模型的预测是词表的所有可用词元上的均匀分布。
在这种情况下,困惑度等于词表中唯一词元的数量。
事实上,如果我们在没有任何压缩的情况下存储序列,
这将是我们能做的最好的编码方式。 因此,这种方式提供了一个重要的上限,
而任何实际模型都必须超越这个上限。
实现部分
一次迭代过程
手动实现
1 2 3 4 5 6 7 8 9 10 import mathimport torchfrom torch import nnfrom torch.nn import functional as Ffrom d2l import torch as d2l32 , 35
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def get_params (vocab_size, num_hiddens, device ):def normal (shape ):return torch.randn(size=shape, device=device) * 0.01 for param in params:True )return paramsdef init_rnn_state (batch_size, num_hiddens, device ):return (torch.zeros((batch_size, num_hiddens)), device=device),)
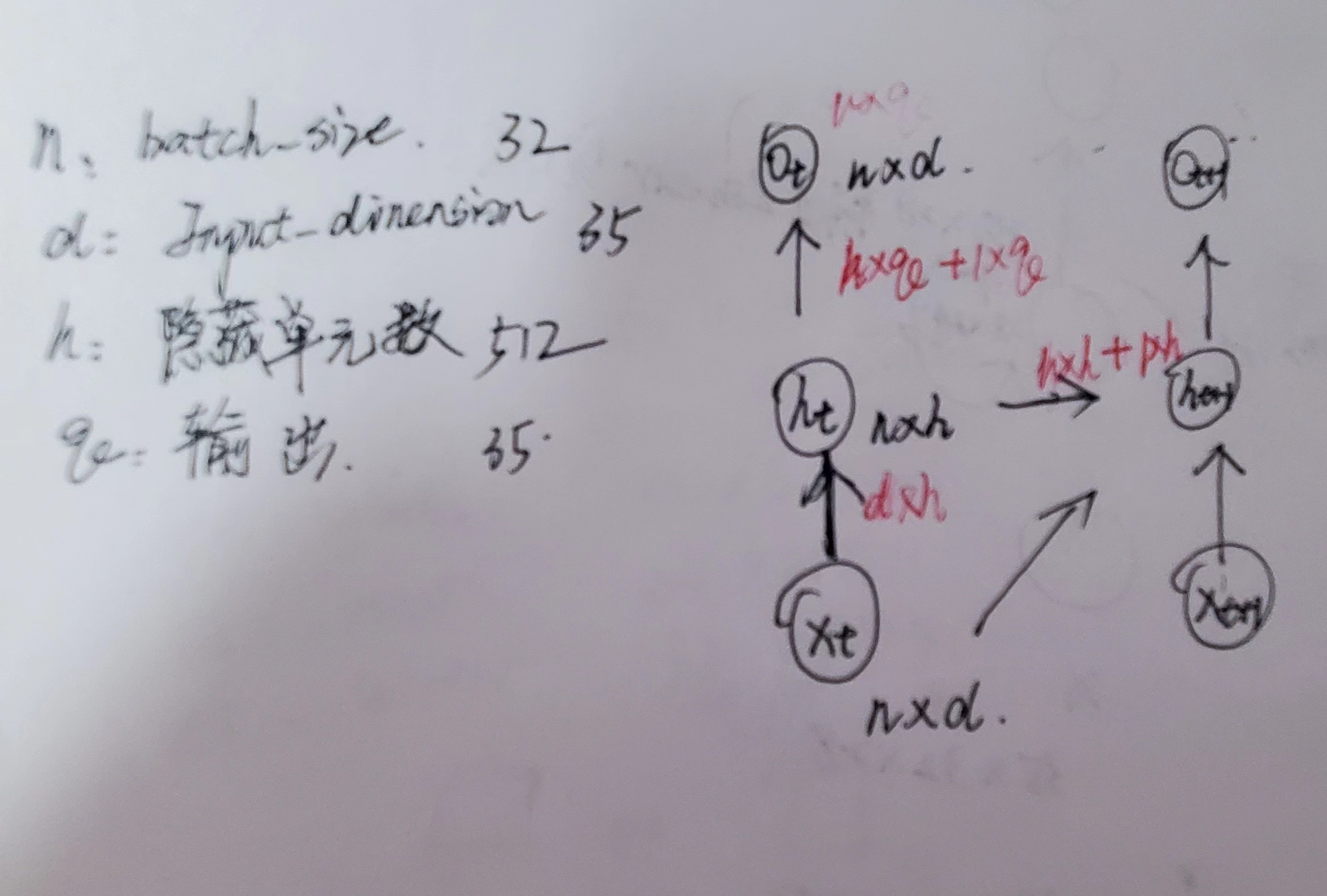
隐藏层输入输出与参数
1 2 3 4 5 6 7 8 9 10 11 12 def rnn (inputs, state, params ):for X in inputs:return torch.cat(outputs, dim=0 ), (H,)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class RNNModelScratch : """从零开始实现的循环神经网络模型""" def __init__ (self, vocab_size, num_hiddens, device, get_params, init_state, forward_fn ):def __call__ (self, X, state ):type (torch.float32)return self.forward_fn(X, state, self.params)def begin_state (self, batch_size, device ):return self.init_state(batch_size, self.num_hiddens, device)
1 2 3 num_hiddens = 512 len (vocab), num_hiddens, d2l.try_gpu(), get_params,
1 2 3 4 5 6 7 8 9 10 11 12 13 def predict_ch8 (prefix, num_preds, net, vocab, device ): """在prefix后面生成新字符""" 1 , device=device)0 ]]]lambda : torch.tensor([outputs[-1 ]], device=device).reshape((1 , 1 ))for y in prefix[1 :]: for _ in range (num_preds): int (y.argmax(dim=1 ).reshape(1 )))return '' .join([vocab.idx_to_token[i] for i in outputs])
1 2 3 4 5 6 7 8 9 10 def grad_clipping (net, theta ): """裁剪梯度""" if isinstance (net, nn.Module):for p in net.parameters() if p.requires_grad]else :sum (torch.sum ((p.grad ** 2 )) for p in params))if norm > theta:for param in params:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 def train_epoch_ch8 (net, train_iter, loss, updater, device, use_random_iter ):"""训练网络一个迭代周期(定义见第8章)""" None , d2l.Timer()2 ) for X, Y in train_iter:if state is None or use_random_iter:0 ], device=device)else :if isinstance (net, nn.Module) and not isinstance (state, tuple ):else :for s in state:1 )if isinstance (updater, torch.optim.Optimizer):1 )else :1 )1 )return math.exp(metric[0 ] / metric[1 ]), metric[1 ] / timer.stop()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def train_ch8 (net, train_iter, vocab, lr, num_epochs, device, use_random_iter=False ):"""训练模型(定义见第8章)""" 'epoch' , ylabel='perplexity' ,'train' ], xlim=[10 , num_epochs])if isinstance (net, nn.Module):else :lambda batch_size: d2l.sgd(net.params, lr, batch_size)lambda prefix: predict_ch8(prefix, 50 , net, vocab, device)for epoch in range (num_epochs):if (epoch + 1 ) % 10 == 0 :print (predict('time traveller' ))1 , [ppl])print (f'困惑度 {ppl:.1 f} , {speed:.1 f} 词元/秒 {str (device)} ' )print (predict('time traveller' ))print (predict('traveller' ))
1 2 3 4 5 6 500 , 1 'time traveller ' , 10 , net, vocab, d2l.try_gpu())
简洁实现
1 2 3 4 5 6 7 import torchfrom torch import nnfrom torch.nn import functional as Ffrom d2l import torch as d2l32 , 35
1 2 3 4 5 6 7 8 256 len (vocab), num_hiddens)1 , batch_size, num_hiddens))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class RNNModel (nn.Module):"""循环神经网络模型""" def __init__ (self, rnn_layer, vocab_size, **kwargs ):super (RNNModel, self).__init__(**kwargs)if not self.rnn.bidirectional:1 else :2 2 , self.vocab_size)def forward (self, inputs, state ):1 , Y.shape[-1 ])))return output, statedef begin_state (self, device, batch_size=1 ):if not isinstance (self.rnn, nn.LSTM):return torch.zeros((self.num_directions * self.rnn.num_layers,else :return (torch.zeros((
1 2 3 4 5 6 7 8 device = d2l.try_gpu()len (vocab))500 , 1 'time traveller' , 10 , net, vocab, device)